Querying Queues and Workers
Managing task queues and monitoring the associated workers is a common necessity in many applications. To facilitate these interactions, Merlin offers two essential commands – Queue Information and Query Workers.
This module will delve into the details of these commands, providing insights into how to effectively retrieve information about task queues and query workers.
Queue Information
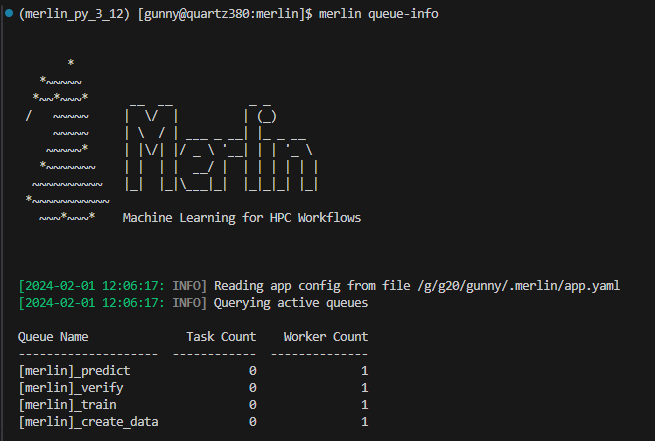
Merlin provides users with the merlin queue-info command to help monitor celery queues. This command will list queue statistics in a table format where the columns are as follows: queue name, number of tasks in the queue, number of workers connected to the queue.
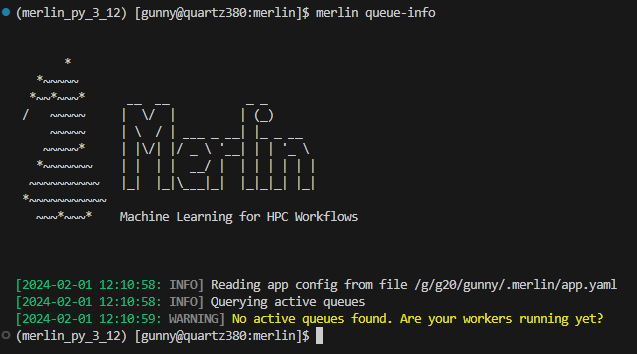
The default functionality of this command is to display queue statistics for active queues. Active queues are any queues that have a worker watching them.
Usage:
Example Queue-Info Output With No Active Queues
Example Queue-Info Output With Active Queues
Basic Options
The queue-info command comes equipped with some basic options:
--dump: Dump the queue information to a.csvor.jsonfile--specific-queues: Only obtain queue information for queues you list here--task-server: Modify the task server value
Dump
Much like the two status commands, the queue-info command provides a way to dump the queue statistics to an output file.
When dumping to a file that does not yet exist, Merlin will create that file for you and populate it with the queue statistics you requested.
When dumping to a file that does exist, Merlin will append the requested queue statistics to that file. You can differentiate between separate dump calls by looking at the timestamps of the dumps. For CSV files this timestamp exists in the Time column (see CSV Dump Format below) and for JSON files this timestamp will be the top level key to the queue info entry (see JSON Dump Format below).
Using any of the --specific-steps, --spec, or --steps options will modify the output that's written to the output file.
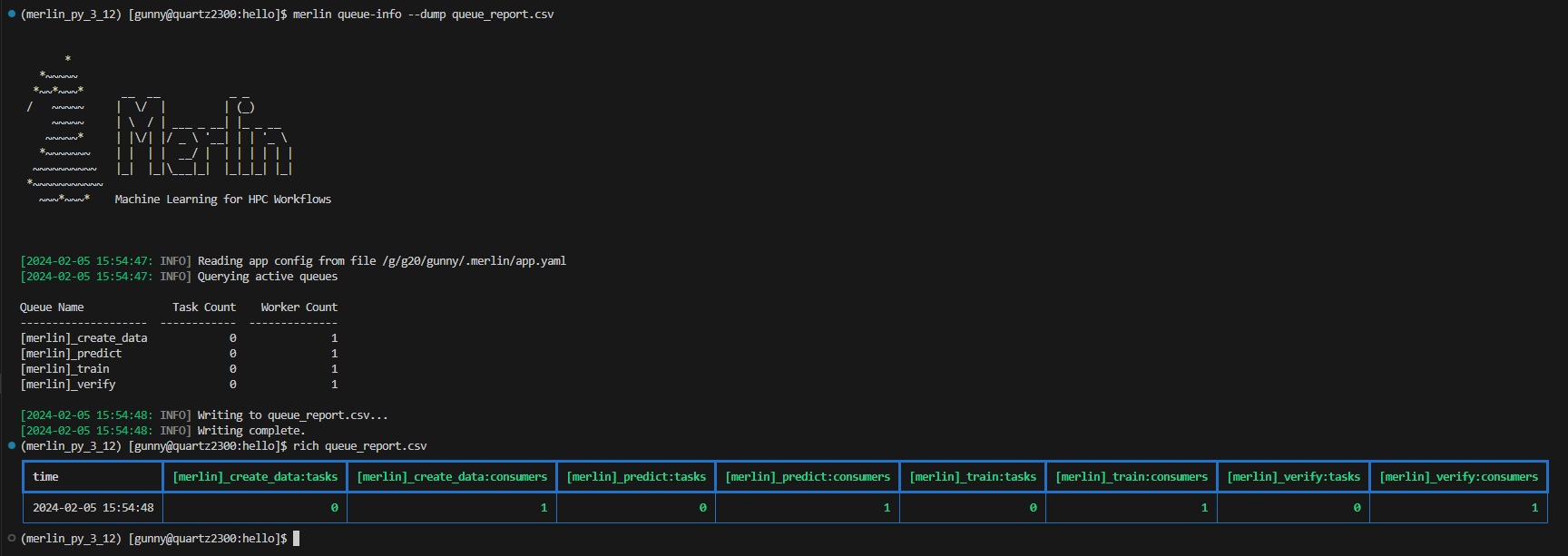
CSV Dump Format
The format of a CSV dump file for queue information is as follows:
The <queue_name>:tasks and <queue_name>:consumers columns will be created for each queue that's listed in the queue-info output at the time of your dump.
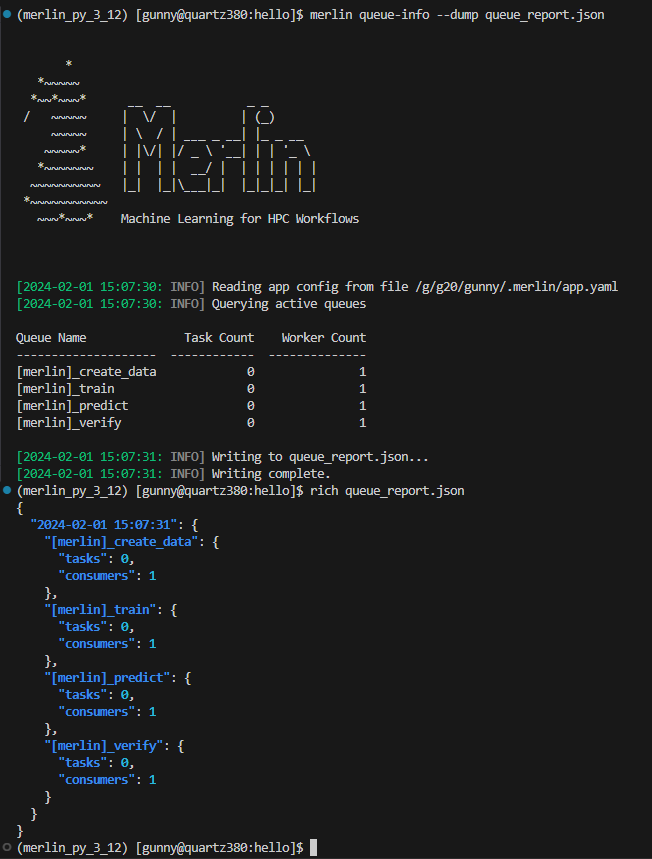
The image below shows an example of dumping the queue statistics of active queues to a csv file, and then displaying that csv file using the rich-cli library:
JSON Dump Format
The format of a JSON dump file for queue information is as follows:
{
"YYYY-MM-DD HH:MM:SS": {
"[merlin]_queue_name": {
"tasks": <integer>,
"consumers": <integer>
}
}
}
The image below shows an example of dumping the queue info to a json file, and then displaying that json file using the rich-cli library:
Specific Queues
If you know exactly what queues you want to check on, you can use the --specific-queues option to list one or more queues to view.
Usage:
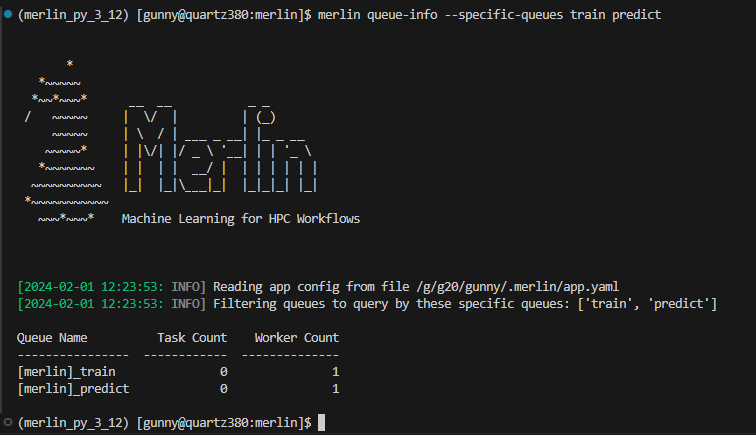
Example Queue-Info Output Using Specific-Queues With Active Queues
In the example below, we're querying the train and predict queues which both have a worker watching them currently (in other words, they are active).
If you ask for queue-info of inactive queues with the --specific-queues option, a table format will still be output for you.
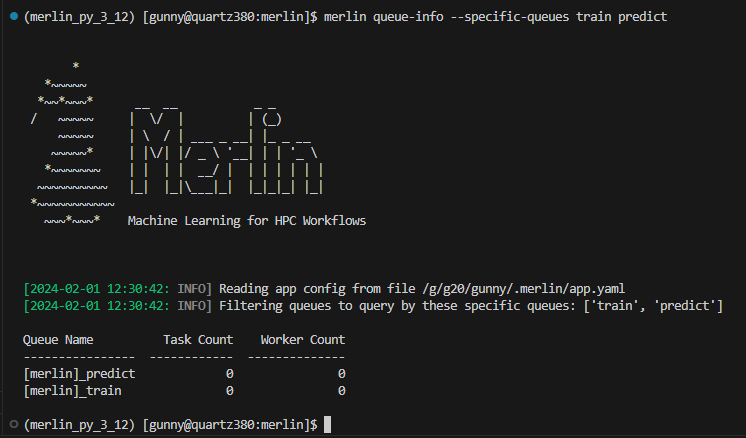
Example Queue-Info Output Using Specific-Queues With Inactive Queues
In the example below, we're querying the train and predict queues which both don't have a worker watching them currently (in other words, they are inactive).
Task Server
To modify the task server from the command line you can use the --task-server option. However, the only currently available option for task server is celery so you most likely will not want to use this option.
Usage:
Specification Options
There are three options with the --queue-info command that revolve around using a spec file to query queue information:
--spec: Obtain queue information for all queues defined in a spec file--steps: Obtain queue information for queues attached to certain steps in a spec file--vars: Modify environment variables in a spec from the command line
Note
The --steps and --vars options must be used alongside the --spec option. They cannot be used by themselves.
Spec
Using the --spec option allows you to query queue statistics for queues that only exist in the spec file you provide. This is the same functionality as the merlin status command prior to the release of Merlin v1.12.0.
Usage:
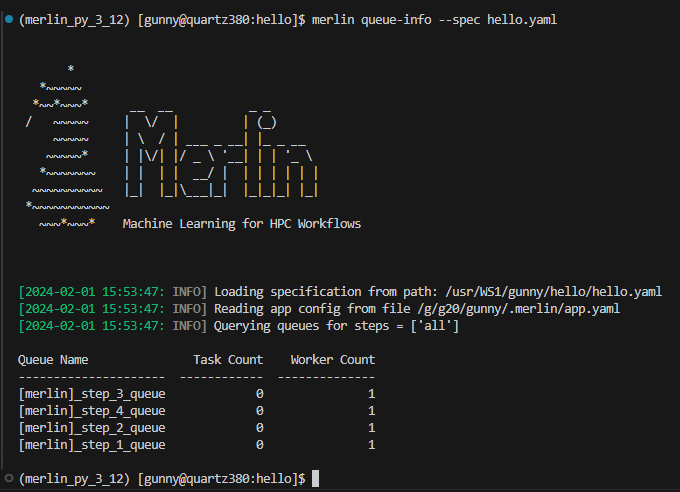
Example Queue-Info Output Using the --spec Option
The below example will display queue information for all queues in the hello.yaml spec file.
Steps
Warning
This option must be used alongside the --spec option.
If you'd like to see queue information for queues that are attached to specific steps in your workflow, use the --steps option.
Usage:
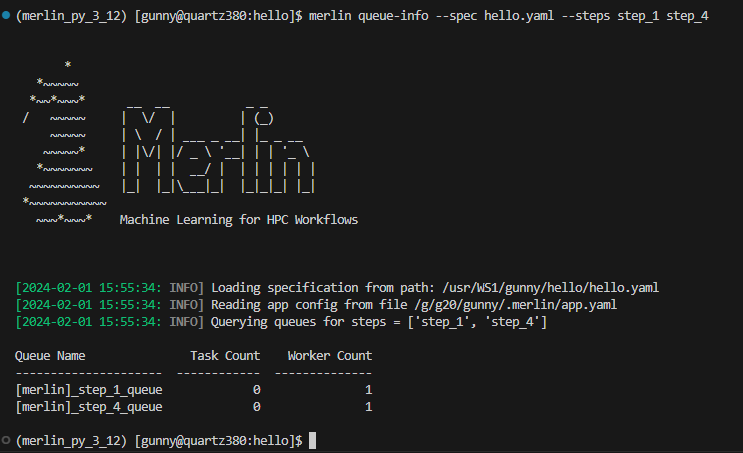
Example Queue-Info Output Using the --steps Option
Say we have a spec file with steps named step_1 through step_4 and each step is attached to a different task queue step_1_queue through step_4_queue respectively. Using the --steps option for these two steps gives us:
Vars
Warning
This option must be used alongside the --spec option.
The --vars option can be used to modify any variables defined in your spec file from the command line interface. This option can take a space-delimited list of variables and their assignments, and should be given after the input yaml file.
Usage:
Example of Using --vars With Queue-Info
Say we have the following spec file with a variable QUEUE_NAME that's referenced in step_2:
description:
name: vars_demo
description: a very simple merlin workflow
env:
variables:
QUEUE_NAME: step_2_queue
study:
- name: step_1
description: say hello
run:
cmd: echo "hello!"
task_queue: step_1_queue
- name: step_2
description: print a success message
run:
cmd: print("Hurrah, we did it!")
depends: [step_1_*]
shell: /usr/bin/env python3
task_queue: $(QUEUE_NAME)
If we decided we wanted to modify this queue at the command line, we could accomplish this with the --vars option of the merlin run and merlin run-workers commands:
Now if we were to try to query the queue information without using the same --vars argument:
...we see step_1_queue and step_2_queue but we wouldn't see new_queue_name:
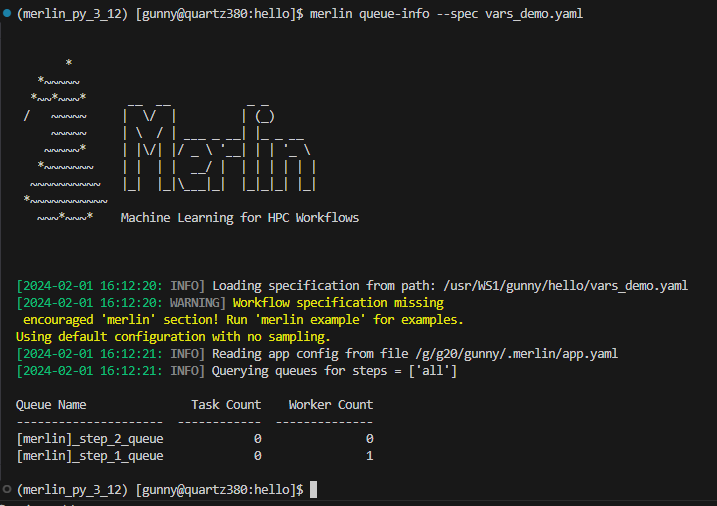
This is due to the fact that when we modify a variable from the command line, the original spec file is not changed.
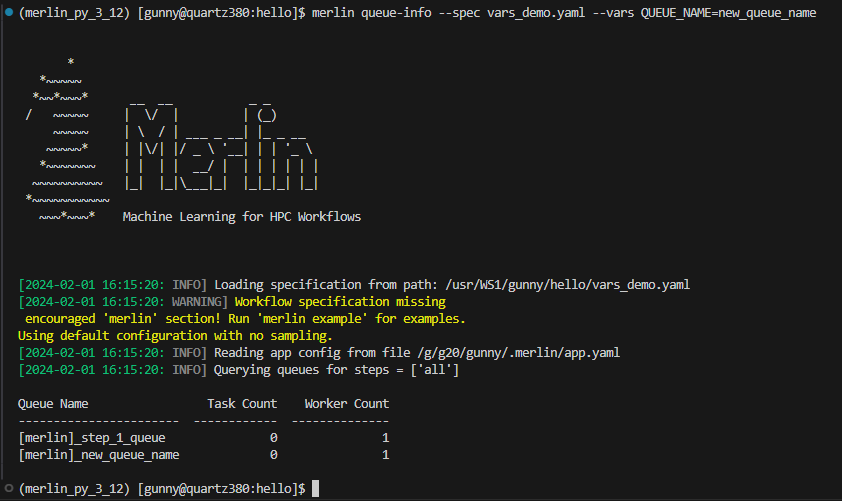
With that being said, let's now run this again but this time we'll use the --vars option:
...which should show us a worker watching the new_queue_name queue:
Query Workers
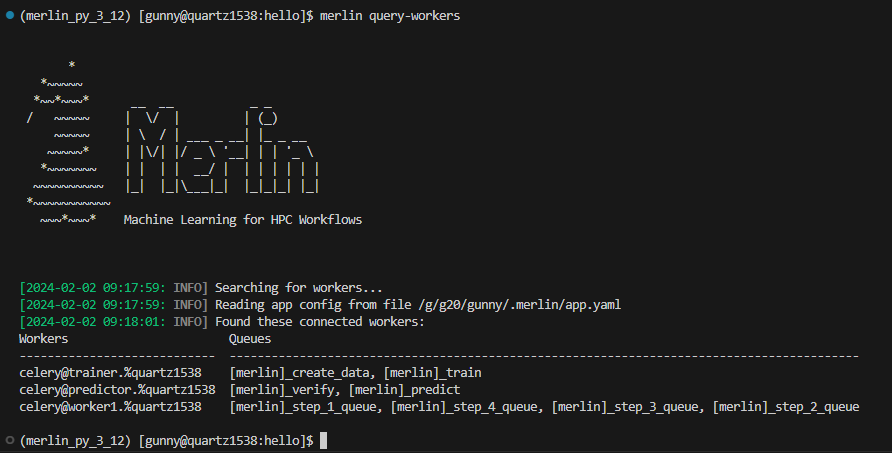
Merlin provides users with the merlin query-workers command to help users see which workers are running and what task queues they're watching.
This command will output content to a table format with two columns: workers and queues. The workers column will contain one connected worker per row. The queues column will contain a comma-delimited list of queues that the connected worker is watching.
Usage:
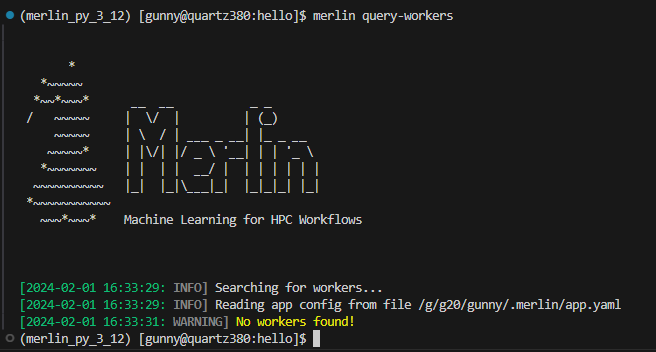
Example Query-Workers Output With No Connected Workers
Example Query-Workers Output With Connected Workers
Query Workers by Spec File
When utilizing the --spec option with the query-workers command, your query will be adjusted to exclusively search for the workers specified in the provided spec file. If none of the workers defined in the spec file have been started, a message indicating this will be displayed.
Usage:
Example of Using the --spec Option With Query-Workers
For this example let's start with two spec files demo_workflow.yaml and demo_workflow_2.yaml. In demo_workflow.yaml we'll have two workers trainer and predictor, and in demo_workflow_2.yaml we'll have one worker worker1.
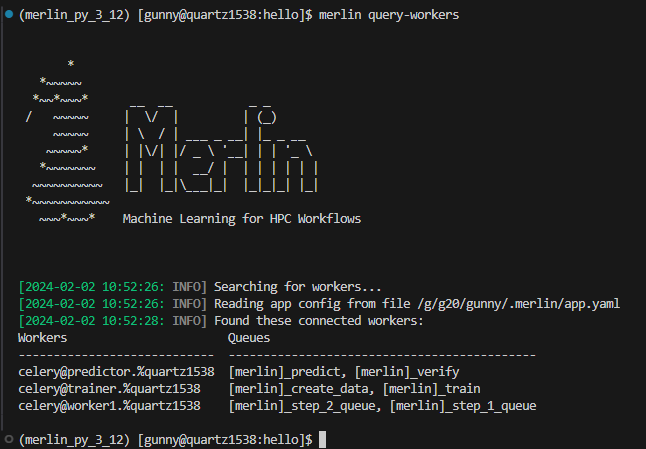
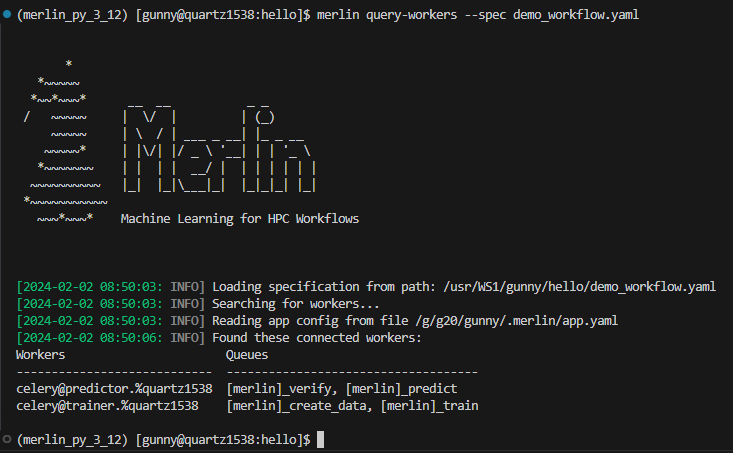
Here, the trainer worker is watching the create_data and train steps which both have task queues of the same name. Therefore, the trainer worker will be watching the create_data and train task queues. Similarly, the predictor worker will be watching the predict and verify task queues.
description:
name: demo_workflow
description: a very simple merlin workflow
study:
- name: create_data
description: create data for our model to train with
run:
cmd: echo "creating data"
task_queue: create_data
- name: train
description: train a model
run:
cmd: echo "training a model on the data"
task_queue: train
- name: predict
description: predict on unseen data
run:
cmd: echo "predict on new, unseen data"
task_queue: predict
- name: verify
description: verify the validity of our study
run:
cmd: echo "verify our study succeeded"
task_queue: verify
merlin:
resources:
workers:
trainer:
args: -l INFO
steps: [create_data, train]
predictor:
args: -l INFO
steps: [predict, verify]
In this workflow, the worker1 worker is assigned to both step_1 and step_2. Therefore, this worker will be connected to both step_1_queue and step_2_queue.
description:
name: $(NAME)
description: a very simple merlin workflow
env:
variables:
NAME: hello
OUTPUT_PATH: ./studies
global.parameters:
GREET:
values : ["hello","hola"]
label : GREET.%%
WORLD:
values : ["world","mundo"]
label : WORLD.%%
study:
- name: step_1
description: say hello
run:
cmd: echo "$(GREET), $(WORLD)!"
task_queue: step_1_queue
- name: step_2
description: print a success message
run:
cmd: print("Hurrah, we did it!")
depends: [step_1_*]
shell: /usr/bin/env python3
task_queue: step_2_queue
merlin:
resources:
workers:
worker1:
args: -l INFO
steps: [all]
Let's start these workers with:
Now if we used the query-workers command without the --spec option, we'd see all three workers across both workflows: trainer, predictor, and worker1:
Great, but what if we wanted to see just the workers for demo_workflow.yaml? We can accomplish this by using the --spec option:
Now, we'll notice that the only workers being displayed are trainer and predictor:
Query Workers by Queues
In Merlin, newly spawned workers are linked to task queues either as assigned by you or automatically designated if not specified. Utilizing the --queues option in the query-workers command enables you to query workers based on the queues to which they are connected.
Usage:
Example of Using the --queues Option With Query-Workers
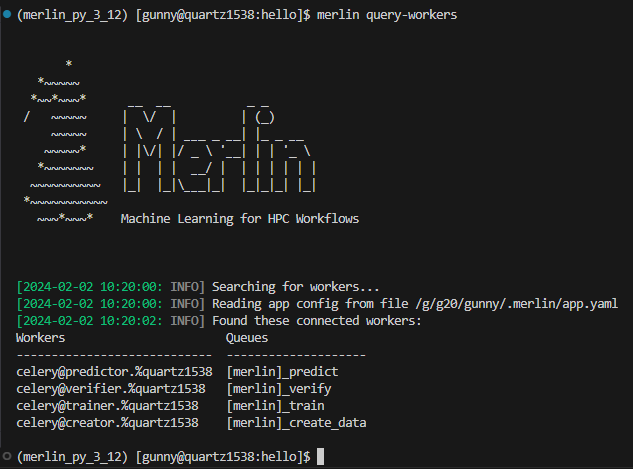
Say we have the below spec file with four workers creator, trainer, predictor, and verifier that are each attached to their respective steps/task queues. In other words, creator will be connected to the create_data task queue, trainer will be connected to the train task queue, etc.:
description:
name: demo_workflow
description: a very simple merlin workflow
study:
- name: create_data
description: create data for our model to train with
run:
cmd: echo "creating data"
task_queue: create_data
- name: train
description: train a model
run:
cmd: echo "training a model on the data"
task_queue: train
- name: predict
description: predict on unseen data
run:
cmd: echo "predict on new, unseen data"
task_queue: predict
- name: verify
description: verify the validity of our study
run:
cmd: echo "verify our study succeeded"
task_queue: verify
merlin:
resources:
workers:
creator:
args: -l INFO
steps: [create_data]
trainer:
args: -l INFO
steps: [train]
predictor:
args: -l INFO
steps: [predict]
verifier:
args: -l INFO
steps: [verify]
We can start these workers with:
Now if we query the workers without the --queues option, we'll see all four workers alive and connected to their respective queues:
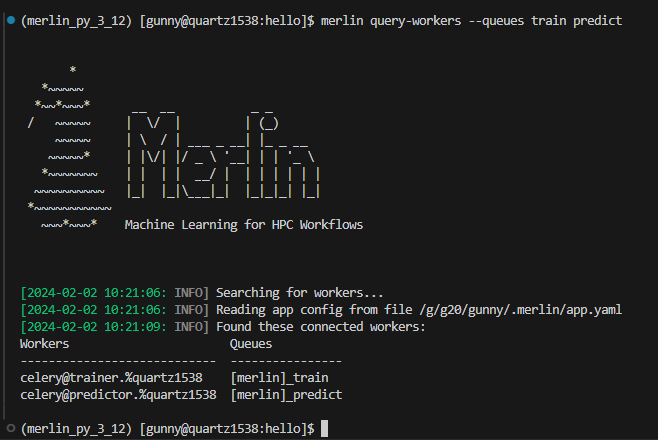
Let's refine this query to just view the workers connected to the train and predict queues:
As we can see in the output below, only the trainer and predictor workers are now displayed:
Query Workers by Worker Regex
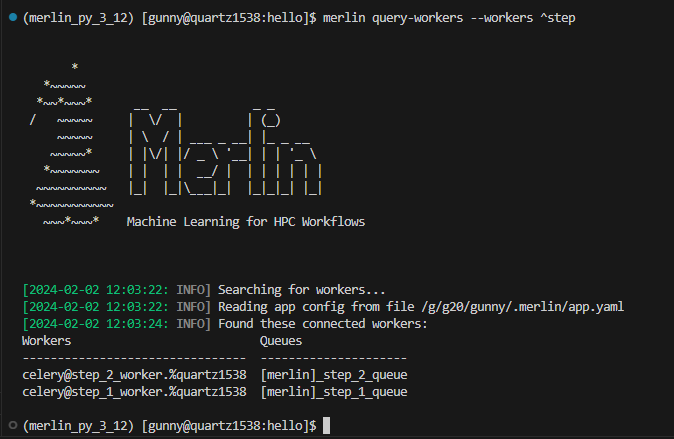
There will be instances when you know precisely which workers you want to query. In such cases, the --workers option in the query-workers command proves useful. This option facilitates querying workers using regular expressions. As full strings are accepted as regular expressions, you can also query workers by worker name.
Usage:
Example of Using the --workers Option With Query-Workers
Say we have the following spec file with 3 workers step_1_worker, step_2_worker, and other_worker:
description:
name: demo_workflow
description: a very simple merlin workflow
study:
- name: step_1
description: A step following the `step_*` name pattern
run:
cmd: echo "step 1"
task_queue: step_1_queue
- name: step_2
description: A step following the `step_*` name pattern
run:
cmd: echo "step 2"
task_queue: step_2_queue
- name: other_step
description: A step with a different name
run:
cmd: echo "other step"
task_queue: predict
merlin:
resources:
workers:
step_1_worker:
args: -l INFO
steps: [step_1]
step_2_worker:
args: -l INFO
steps: [step_2]
other_worker:
args: -l INFO
steps: [other_step]
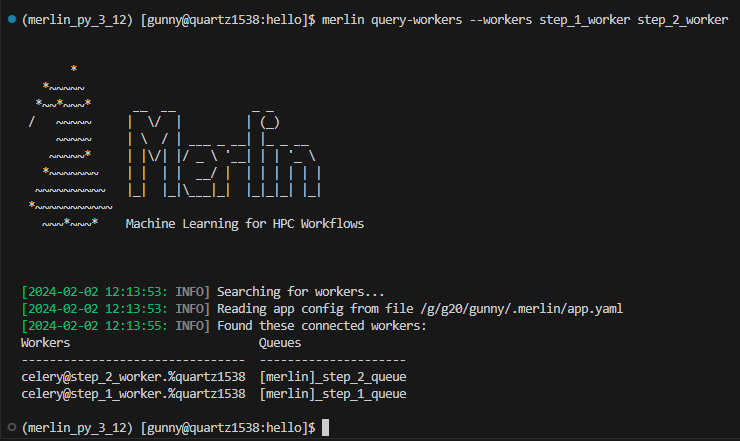
Once the workers are started for this workflow, we can then query for our step_1_worker and step_2_worker with:
In our output we see that both workers that we asked for were queried but other_worker was ignored:
Alternatively, we can do the exact same query using a regular expression:
The ^ operator for regular expressions will match the beginning of a string. In this example when we say ^step we're asking Merlin to match any worker starting with the word step, which in this case is step_1_worker and step_2_worker. We can see this in the output below: