
Merlin
Empower your projects with Merlin, a cloud-based workflow manager designed to facilitate scalable and reproducible workflows, particularly suited for running many simulations and iterative procedures.
Why Merlin?
Workflows, applications and machines are becoming more complex, but subject matter experts need to devote time and attention to their applications and often require fine command-line level control. Furthermore, they rarely have the time to devote to learning workflow systems.
With the expansion of data-driven computing, the HPC scientist needs to be able to run more simulations through complex multi-component workflows.
Merlin targets HPC workflows that require many simulations.1
Goals and Motivations
Merlin was created with the intention of providing flexible and reproducible workflows to users at a scale that could be much larger than Maestro. Since Merlin is built as an extension of Maestro, we wanted to maintain Maestro's Goals and Motivations while at the same time providing users the ability to become their own big-data generator.
In the pursuit of flexible and reproducible worflows, Merlin places a paramount emphasis on workflow provenance. We recognize the importance of understanding how workflows evolve, ensuring that every decision, parameter adjustment, and execution is meticulously documented. Workflow provenance is not just a feature for us; it's a fundamental element that contributes to the reliability and trustworthiness of your studies.
Merlin understands the dynamic nature of your work, especially when dealing with large-scale simulations. Our goal is to provide a platform that seamlessly scales to accommodate the computational demands of extensive simulations, ensuring that your workflows remain efficient and effective, even in the face of substantial computational requirements.
Getting Started
Install Merlin
Merlin can be installed via pip in your own virtual environment.
-
First, create a virtual environment:
-
Now activate the virtual environment:
-
Finally, install Merlin with pip:
Create a Containerized Server
First, let's create a folder to store our server files and our examples. We'll also move into this directory:
Now let's set up a containerized server that Merlin can connect to.
-
Initialize the server files:
-
Start the server:
-
Copy the
app.yamlconfiguration file frommerlin_server/to your current directory: -
Check that your server connection is working properly:
Your broker and results server should both look like so:
Run an Example Workflow
Let's download Merlin's built-in "Hello, World!" example:
Now that we've downloaded the example, enter the hello/ directory:
In this directory there are files named hello.yaml and hello_samples.yaml. These are what are known as Merlin specification (spec) files. The hello.yaml spec is a very basic example that will also work with Maestro. We'll focus on hello_samples.yaml here as it has more Merlin specific features:
description: # (1)
name: hello_samples
description: a very simple merlin workflow, with samples
env:
variables: # (2)
N_SAMPLES: 3
global.parameters:
GREET: # (3)
values : ["hello","hola"]
label : GREET.%%
study:
- name: step_1
description: say hello
run: # (4)
cmd: |
echo "$(GREET), $(WORLD)!"
- name: step_2
description: print a success message
run: # (5)
cmd: print("Hurrah, we did it!")
depends: [step_1_*] # (6)
shell: /usr/bin/env python3
merlin:
resources:
workers: # (7)
demo_worker:
args: -l INFO --concurrency=1
steps: [all]
samples: # (8)
generate:
cmd: python3 $(SPECROOT)/make_samples.py --filepath=$(MERLIN_INFO)/samples.csv --number=$(N_SAMPLES)
file: $(MERLIN_INFO)/samples.csv
column_labels: [WORLD]
- Mandatory name and description fields to encourage well documented workflows
- Define single valued variable tokens for use in your workflow steps
- Define parameter tokens of the form
$(NAME)and lists of values to use in your steps such that Merlin can parameterize them for you - Here,
cmdis a multline string written in bash to harness the robust existing ecosystem of tools users are already familiar with - Here,
cmdis a single line string written in python. Merlin allows users to modify theshellthatcmduses to execute a step - Specify step dependencies using steps'
namevalues to control execution order - Define custom workers to process your workflow in the most efficient manner
- Generate samples to be used throughout your workflow. These can be used similar to parameters; use the
$(SAMPLE_NAME)syntax (as can be seen instep_1)
We have two ways to run the hello_samples.yaml example:
Running the workflow will first convert your steps into a task execution graph and then create a workspace directory with the results of running your study.
The directed acyclic graph (DAG) that's created for the hello_samples.yaml example will look like so:
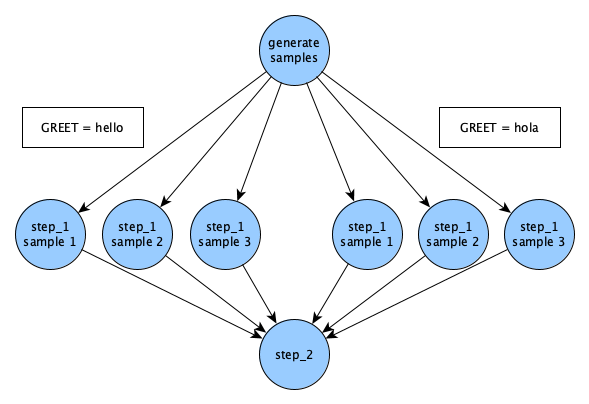
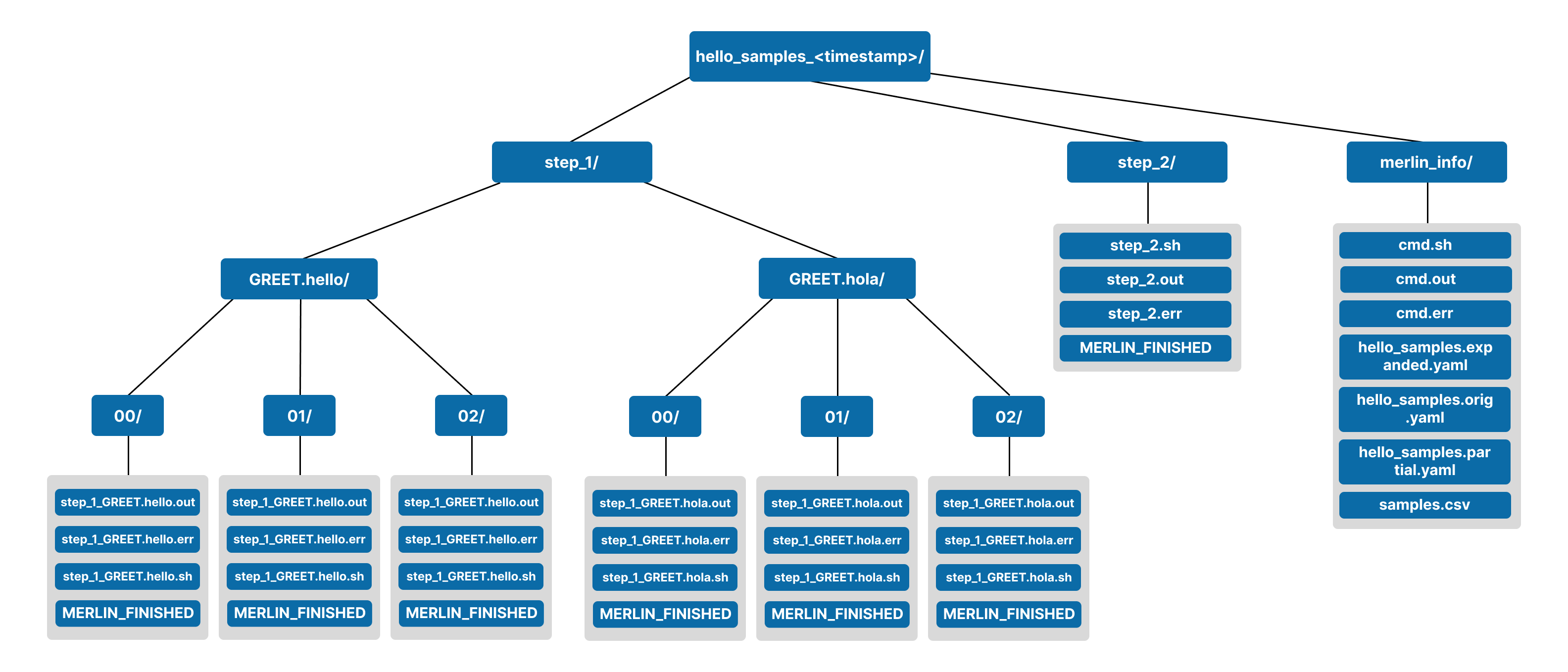
If ran successfully, a workspace for your run should've been created with the name hello_samples_<timestamp>/. Below shows the expected contents of this workspace:
Contents of hello_samples_<timestamp>
Release
Merlin is released under an MIT license. For more information, please see the LICENSE.
LLNL-CODE-797170
-
See Enabling Machine Learning-Ready HPC Ensembles with Merlin for a paper that mentions a study with up to 40 million simulations. ↩